6 minutes
Subdomain Enumeration:Build yourn own tool

Hello security enthusiasts welcome to yet another blog. In this blog, we will learn how to create a simple subdomain enumeration tool with python. Subdomain enumeration is a critical step in recon since understanding digital assets play a major role in every pentest activity. For the same, we have a various set of tools and techniques created by awesome people in the hacking community. Sublister, Amass, and the list goes on. But my question is “Do you have one of your own?”. If your answer is no, then it should not come as a big surprise to me. Because we are from different backgrounds, some may know how to code, some may not be interested in coding, and some may prefer to use a custom tool. Anyway, let’s see if we can build a simple tool with basic Python knowledge.
The source
Yes, we need some source to fetch or scrape the required information. Most of the modern tools try to scrape already existing webpages or make use of open-source API calls to fetch this information. In this case, we will make use of crt.sh. It is an online database of certificate transparency logs. To find the certificates issued to a particular domain, you just have to input the domain name and hit enter. It will pull out all the logged information related to that particular domain.
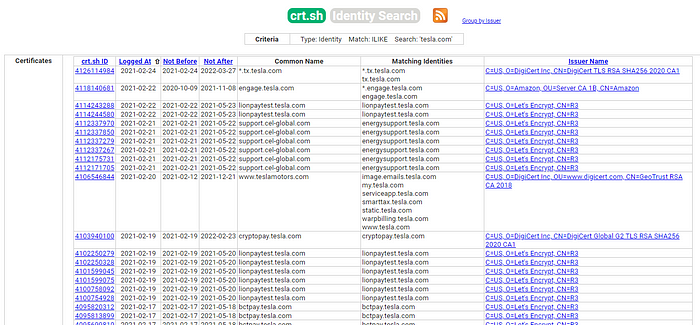
However, going to a website and searching isn’t always convenient, and this will consume more time as compared to an automated tool output. For more complex queries, crt.sh offers direct database access, and custom PostgreSQL queries but we are not going to talk about that here. What we’ll be focusing on will be how to extract relevant information from the table that is already presented to us.
The logic
Since we have the source it’s time to implement the logic. Let’s first analyze the request. It is a basic GET request to https://crt.sh/?q=domain and you get the results. Upon analyzing the response (webpage) you might have noticed that for details regarding subdomain we only need information from the 5th and 6th column and if we don’t care about CNMAE then it narrow down to the 6th column specifically. If we could somehow parse the response, delete the unwanted items, and remove duplicate entries then we might have what we are looking for.
The code
Now we know how the tool should work it’s time to code. Let’s see the necessary python libraries to satisfy our needs.
- requests library for HTTP requests and responses
- sys module to pass arguments from the command line. Because no good tool uses hard-coded information.
- re the Regular Expression library for match and replace. Trust me this library does the magic.
The first part will be importing all the required libraries. Which goes by the syntax
import library-name
You could import all the libraries in a single line by mentioning them as comma-separated values. But we will import them separately 😄
import sys
import requests
import re
The first step will be to send a GET request with the passed domain name to https://crt.sh/?q=. For that, we’ll make use of the requests library and the syntax will be
requests.get(“https://crt.sh/?q=”)
But we are not bothered about the request what we need is the response that we got for the query. It is also simple,
response = requests.get(“https://crt.sh/?q=”)
In the above code, we are saving the response for our request to the response variable. Also, we don’t want to issue an empty query we need to input the domain name and it should be accepted from the command line (from where the tool is run). For that, we will pass the domain name.
import sys
import requests
import re
response = requests.get(“https://crt.sh/?q=”+sys.argv[1])
Here we are issuing a GET request with the first argument passed from the command line(sys.argv[1]). Now let’s analyze the response we got for the same. For that, add the print(response.text) to the bottom of the code.
import sys
import requests
import re
response = requests.get(“https://crt.sh/?q=”+sys.argv[1])
print(response.text)
Because if you just print the response then it will only give you the status code which is 200 in this case. In order to retrieve the webpage source we needed, we must specify it as response.text. Now let’s analyze the response for tesla.com
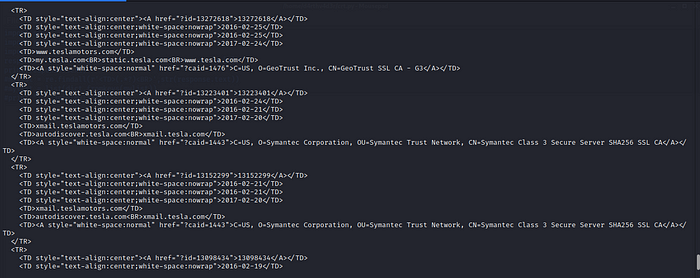
You might’ve already noticed the information we needed lies on the table cell. If we could somehow extract only this information then our tool will be almost done.
It is time for the regular expression. We’ll search for valid domain names in the output that we got. For that, we’ll pass the above response as a string (because re expects string input) to re.findall() function which literally searches for a given regex in the provided string.
import sys
import requests
import re
response = requests.get(“https://crt.sh/?q=”+sys.argv[1])
mylist = re.findall(‘(?:[a-z0–9](?:[a-z0–9-]{0,61}[a-z0–9])?\.)+[a-z0–9][a-z0–9-]{0,61}[a-z0–9]’,str(response.text))
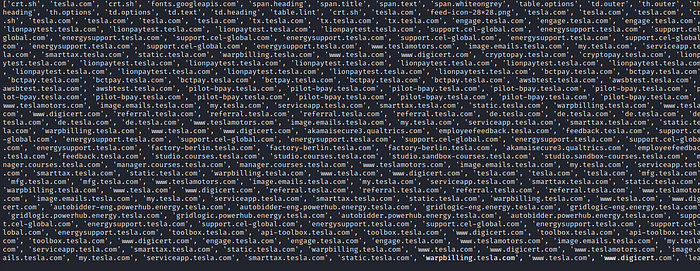
We pass the response to the regular expression to extract only valid domain names. As you can see after this step we are left with a list of domain names. Now it is time to remove duplicates. We’ll make use of the dict.formkeys() method to remove redundant entries from the list.
import sys
import requests
import re
response = requests.get(“https://crt.sh/?q=”+sys.argv[1])
mylist = re.findall(‘(?:[a-z0–9](?:[a-z0–9-]{0,61}[a-z0–9])?\.)+[a-z0–9][a-z0–9-]{0,61}[a-z0–9]’,str(response.text))
mylist = list(dict.formkeys(mylist))
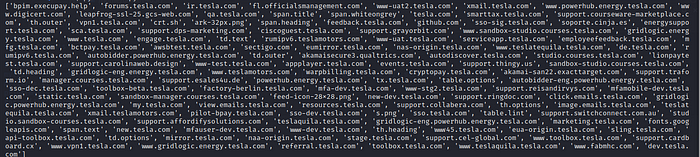
The new dictionary will then be converted back to a list using the list() method. Now we will rollback the list to string and print each entry in a different line using join().
import sys
import requests
import re
response = requests.get(“https://crt.sh/?q=”+sys.argv[1])
mylist = re.findall(‘(?:[a-z0–9](?:[a-z0–9-]{0,61}[a-z0–9])?\.)+[a-z0–9][a-z0–9-]{0,61}[a-z0–9]’,str(response.text))
mylist = list(dict.formkeys(mylist))
print(“\n”,join(mylist))
All set. Time to run the code 😅.
python crt.py tesla.com
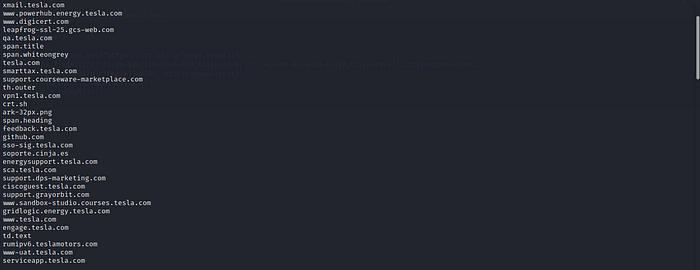
As you can see all the relevant subdomains are enumerated within seconds with only seven lines of code 😄. But, there is a problem. If you’ve noticed for the regular expression td.text & th.outer (HTML properties) are also a valid domain name. How to remove these? since we don’t want this to be included in our final list. One way is to identify all the list items that has “.com” as part of it and retrieve only those information.It’s is not a complete solution but for the sake of this tutorial we are gonna make use of it. We’ll retrieve the TLD from the input argument and try retrieving only those list items which contain that as a substring. We need to first identify the TLD from input argument. If you are passing domain.com as input then our TLD variable must contain the value ‘.com’.
TLD = sys.argv[1].partition(‘.’)
The above code will split our input as [‘domain’ , ’.’ , ’com’] and we only need the third item or simply TLD[2].
TLD = ‘.’+TLD[2]
Finally we will concatenate the same with a ‘.’ since we will be searching for ‘.com’ substring. For searching the substring in our list we will use,
mylist = [x for x in mylist if all(ch in x for ch in TLD)]
Adding this in our enumeration tool will remove all the unwanted items and give a better output.
import sys
import requests
import re
TLD = sys.argv[1].partition(‘.’)
TLD = ‘.’+TLD[2]
response = requests.get(“https://crt.sh/?q=”+sys.argv[1])
mylist = re.findall(‘(?:[a-z0–9](?:[a-z0–9-]{0,61}[a-z0–9])?\.)+[a-z0–9][a-z0–9-]{0,61}[a-z0–9]’,str(response.text))
mylist = [x for x in mylist if all(ch in x for ch in TLD)]
mylist = list(dict.formkeys(mylist))
print(“\n”,join(mylist))
And that’s it. That is all we needed for our subdomain enumeration tool. You could simply input any domain and have a list of subdomains 😉.